인코딩
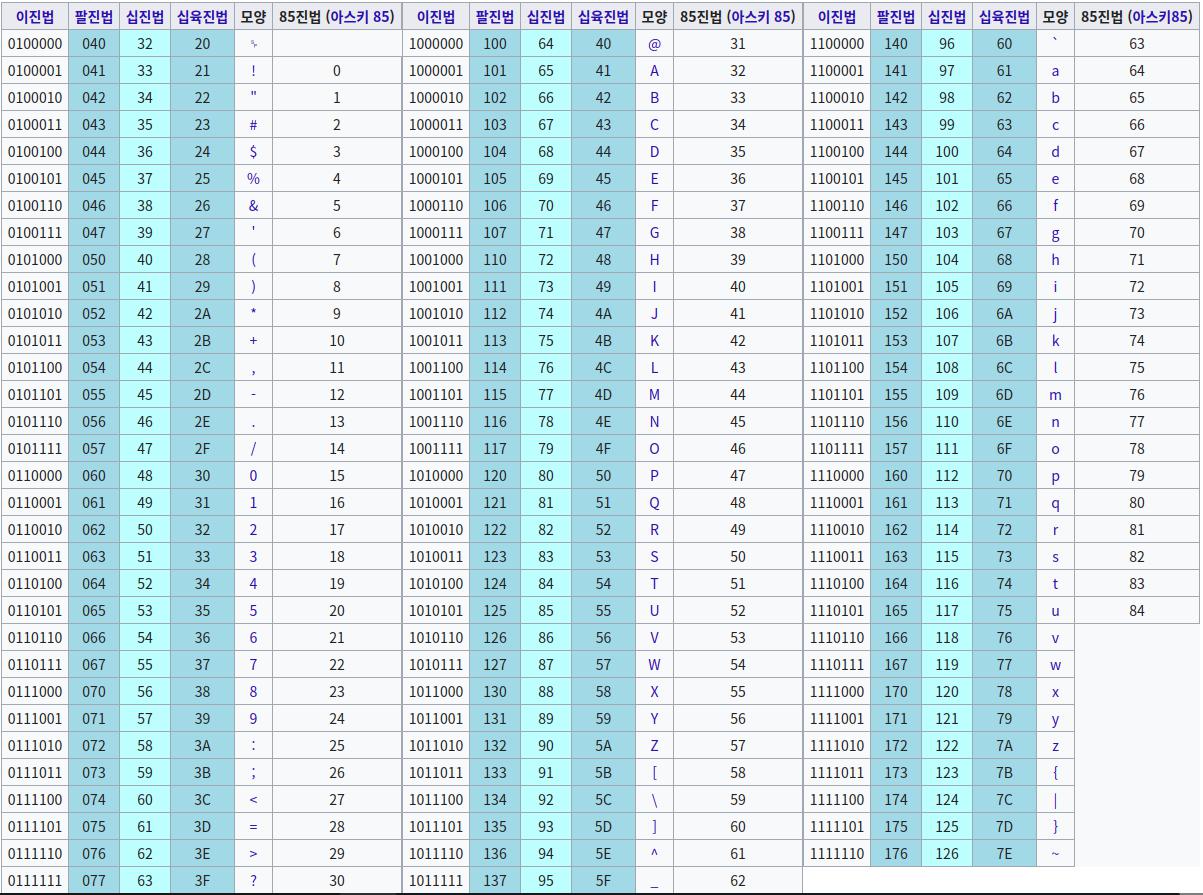
아스키코드표(보통 126개를 사용하지만 255까지 존재함.. 255번째가 0xFF)
아스키코드(1바이트)
- 표기 16진수 하나 0xFF
유니코드(2바이트)
- 표기 16진수 두개 u+AC00
- 모든글자를 2바이트의 유니코드표에 담음
UTF8(1바이트~3바이트)
- 아스키코드와 유니코드이냐에 따라 가변적 바이트
- 아스키+유니코드를 모두 포함한 utf8표에 담음 E7 A0 FF
FF(16진수)에 대해
- 16진수는 8비트 이고 1바이트다
- FF가 16진수 하나이며 4비트+4비트가 합쳐졌으므로 8비트이며 1바이트이다
- FF / 16 / 4+4 = 8 / 1
인코딩(3가지 패턴)
- 8비트(10진수 표기) -> ascii표에서 맞춰서 찾음
- 16비트(16진수2개로 표기) -> unicode표에서 맞춰서 찾음 (u+AC00 : AC:16진수 하나)
- unicode -> utf8표에서 맞춰서 찾음
유니코드 (2바이트)
- 8비트(1바이트)->아스키코드->256글자 (영문)
- 16비트(2바이트)->유니코드->65000글자 (접두어u+) -> 참고로 한글 유니코드는 u+AC00 (가)부터 시작함
- 64비트(4바이트)->유니코드->0x64글자 (접두어u+)
유니코드 한글자 16비트
U+AC00
-
AC가 16진수다
-
00이 16진수다
-
A가 4비트이다 (0에서F까지 16까지 표시함)
-
그러므로 AC 합쳐진 값은 8비트이다
-
AC는 16진수 표기이다
-
AC00는 8비트가 두개 or 16진수가 두개 합쳐진거니까 16비트가된다
-
유니코드는 한글자 16비트이다
7. 16비트는 2바이트다
- 그러므로 유니코드 한글자는 2바이트다
UTF8 (3바이트)
1.유니코드(2바이트)-> UTF8(3바이트)로 바꿈
2.그러나 아스키와 유니코드 둘다 포함해서 가변적으로 인코딩하기 때문에 ascii를 인코딩하는 경우 바이트를 1바이트밖에 소모안함/유니코드일경우엔 3바이트 소모함
3.utf(BOM)은 해당 문서가 utf-8이라는걸 앞에 3바이트를 보이지 않게 추가하는것
URL인코딩
- UTF8(3바이트)사용
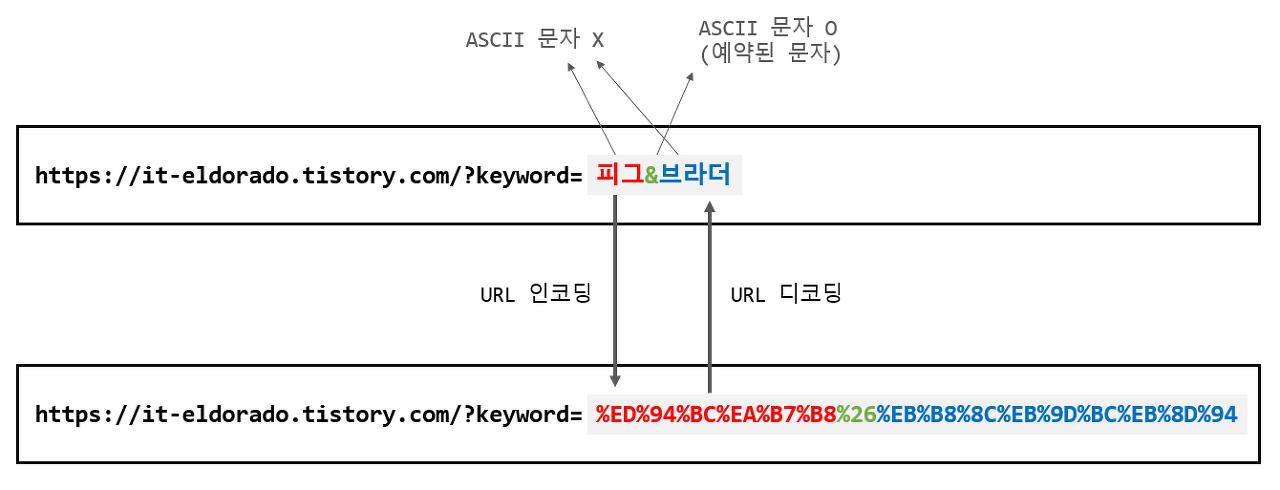 피 => %ED%94%BC (16진수 3개 3바이트)
피 => %ED%94%BC (16진수 3개 3바이트)
문자열 정렬시 이상현상 발생
아래와 같은 현상이 발생하는데 이유는 해당값이 문자열일 경우, 유니코드로 인식이 되기때문에 유니코드를 참조해서 정렬이 발생하기때문이다
유니코드표를 변환한 값을 보면 이해가 된다
(값) (유니코드)
1 u+0031
10 u+0031 u+0030
11 u+0031 u+0031
2 u+0032
3 u+0033
2023년 06월 02일 재정리
A가$ 라는 문자열은 UTF8형식으로 변환시 어떻게 되나?
- 아스키코드와 유니코드를 혼합하여 사용해서 UTF8형식을 만들어 낸다
- 아스키코드: 1바이트
- 유니코드: 2바이트 ~
- 아스키코드와 유니코드 둘다 코드표가 있음
- 아스키코드는 그대로 사용한다
- 유니코드는 UTF8인코딩이 필요하다 ( 아래에 변환과정 설명)
문자: "A"
아스키 코드: 65 (0x41)
UTF-8 인코딩: 41 (1바이트)
문자: "가"
유니코드: 44032 (0xAC00)
UTF-8 인코딩: EAB080 (3바이트) // 실제로 UTF8형식에서 유니코드를 UTF8형식으로 변환하는 과정에서 3바이트를 사용함
문자: "$"
아스키 코드: 36 (0x24)
UTF-8 인코딩: 24 (1바이트)
위의 결과를 UT8형식으로 변환한 결과
(아스키) (유니코드를 UTF8형식으로 변환) (아스키)
41 EAB080 24
유니코드에서 UTF-8형식이 되는 과정
- "가"는 유니코드에서 U+AC00으로 표현됩니다.
- 이 코드 포인트를 UTF-8 형식으로 변환하려면 다음과 같은 단계를 거칩니다.
- "가"의 코드 포인트인 U+AC00을 이진수로 표현합니다. U+AC00은 1010110000000000과 같습니다.
- UTF-8은 다중 바이트로 표현되며, "가"는 3바이트로 표현됩니다.
- 이진수를 다음과 같이 바이트로 나눕니다: 1110xxxx 10xxxxxx 10xxxxxx.
- 상위 4비트를 첫 번째 바이트의 첫 네 비트에 할당합니다. 여기서는 11101010가 됩니다.
- 다음 바이트에는 나머지 6비트를 10xxxxxx 형식으로 할당합니다. 여기서는 10110000이 됩니다.
- 마지막 바이트에도 나머지 6비트를 10xxxxxx 형식으로 할당합니다. 여기서는 10000000이 됩니다.
- 11101010 10110000 10000000를 16진수로 하면 아래와 같은 결과가 된다
- 따라서 "가"는 UTF-8로 변환되면 EAB080이 됩니다. 이는 총 3바이트로 구성됩니다.
요약하면
-
즉 유니코드를 이진수로 변환한다 1010110000000000
-
변환된 이진수를 나눈다
-
이진수를 나눈 분리한 결과는 이와 같다 1010 110000 000000
-
분리된 이진수 앞에 1110xxxx 10xxxxxx 10xxxxxx를 붙여서 나눈다
-
결과가 11101010 10110000 10000000가 된다
-
16진수로 변경한다
-
EAB080가 된다
-
EA/B0/80는 3바이트이다
일본어의 경우 UTF-8で 3~4바이트 사이로 표시가 가능하다
( 한글의 경우에는 byte 3 바이트 고정 )
-
1바이트 문자열: ASCII 코드 범위인 U+0000 ~ U+007F에는 영어 알파벳, 숫자, 일부 기호 등이 포함됩니다. 예를 들어:
A,1,!
-
2바이트 문자열: U+0080 ~ U+07FF 범위의 2바이트 유니코드 인코딩은 주로 라틴어 확장 문자, 그리스어, 키릴 문자 등이 포함됩니다. 예를 들어:
À(U+00C0)Æ(U+00C6)
-
3바이트 문자열: U+0800 ~ U+FFFF 범위는 기본적으로 다국어 문자, 특히 일본어 히라가나, 가타카나, 한자 등이 포함됩니다. 몇 가지 예시는 다음과 같습니다:
あ(히라가나 U+3042)ア(가타카나 U+30A2)漢(한자 U+6F22)
-
4바이트 문자열: U+10000 ~ U+1FFFFF 범위는 주로 확장된 유니코드 문자에 해당하며, 일부 이모티콘이나 희귀 문자 등이 포함됩니다. 예를 들어:
𠀋(U+2000B)𠮷(U+20BB7) → 일본어에서 사용되지 않는 한자등이 사용됨